VertexAI [Anthropic, Gemini, Model Garden]
vertex_ai/ route
The vertex_ai/ route uses uses VertexAI's REST API.
from litellm import completion
import json
## GET CREDENTIALS
## RUN ##
# !gcloud auth application-default login - run this to add vertex credentials to your env
## OR ##
file_path = 'path/to/vertex_ai_service_account.json'
# Load the JSON file
with open(file_path, 'r') as file:
vertex_credentials = json.load(file)
# Convert to JSON string
vertex_credentials_json = json.dumps(vertex_credentials)
## COMPLETION CALL
response = completion(
model="vertex_ai/gemini-pro",
messages=[{ "content": "Hello, how are you?","role": "user"}],
vertex_credentials=vertex_credentials_json
)
System Message
from litellm import completion
import json
## GET CREDENTIALS
file_path = 'path/to/vertex_ai_service_account.json'
# Load the JSON file
with open(file_path, 'r') as file:
vertex_credentials = json.load(file)
# Convert to JSON string
vertex_credentials_json = json.dumps(vertex_credentials)
response = completion(
model="vertex_ai/gemini-pro",
messages=[{"content": "You are a good bot.","role": "system"}, {"content": "Hello, how are you?","role": "user"}],
vertex_credentials=vertex_credentials_json
)
Function Calling
Force Gemini to make tool calls with tool_choice="required".
from litellm import completion
import json
## GET CREDENTIALS
file_path = 'path/to/vertex_ai_service_account.json'
# Load the JSON file
with open(file_path, 'r') as file:
vertex_credentials = json.load(file)
# Convert to JSON string
vertex_credentials_json = json.dumps(vertex_credentials)
messages = [
{
"role": "system",
"content": "Your name is Litellm Bot, you are a helpful assistant",
},
# User asks for their name and weather in San Francisco
{
"role": "user",
"content": "Hello, what is your name and can you tell me the weather?",
},
]
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
}
},
"required": ["location"],
},
},
}
]
data = {
"model": "vertex_ai/gemini-1.5-pro-preview-0514"),
"messages": messages,
"tools": tools,
"tool_choice": "required",
"vertex_credentials": vertex_credentials_json
}
## COMPLETION CALL
print(completion(**data))
JSON Schema
From v1.40.1+ LiteLLM supports sending response_schema as a param for Gemini-1.5-Pro on Vertex AI. For other models (e.g. gemini-1.5-flash or claude-3-5-sonnet), LiteLLM adds the schema to the message list with a user-controlled prompt.
Response Schema
- SDK
- PROXY
from litellm import completion
import json
## SETUP ENVIRONMENT
# !gcloud auth application-default login - run this to add vertex credentials to your env
messages = [
{
"role": "user",
"content": "List 5 popular cookie recipes."
}
]
response_schema = {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
}
completion(
model="vertex_ai/gemini-1.5-pro",
messages=messages,
response_format={"type": "json_object", "response_schema": response_schema} # 👈 KEY CHANGE
)
print(json.loads(completion.choices[0].message.content))
- Add model to config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: vertex_ai/gemini-1.5-pro
vertex_project: "project-id"
vertex_location: "us-central1"
vertex_credentials: "/path/to/service_account.json" # [OPTIONAL] Do this OR `!gcloud auth application-default login` - run this to add vertex credentials to your env
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-D '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"response_format": {"type": "json_object", "response_schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
}}
}
'
Validate Schema
To validate the response_schema, set enforce_validation: true.
- SDK
- PROXY
from litellm import completion, JSONSchemaValidationError
try:
completion(
model="vertex_ai/gemini-1.5-pro",
messages=messages,
response_format={
"type": "json_object",
"response_schema": response_schema,
"enforce_validation": true # 👈 KEY CHANGE
}
)
except JSONSchemaValidationError as e:
print("Raw Response: {}".format(e.raw_response))
raise e
- Add model to config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: vertex_ai/gemini-1.5-pro
vertex_project: "project-id"
vertex_location: "us-central1"
vertex_credentials: "/path/to/service_account.json" # [OPTIONAL] Do this OR `!gcloud auth application-default login` - run this to add vertex credentials to your env
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-D '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"response_format": {"type": "json_object", "response_schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
},
"enforce_validation": true
}
}
'
LiteLLM will validate the response against the schema, and raise a JSONSchemaValidationError if the response does not match the schema.
JSONSchemaValidationError inherits from openai.APIError
Access the raw response with e.raw_response
Add to prompt yourself
from litellm import completion
## GET CREDENTIALS
file_path = 'path/to/vertex_ai_service_account.json'
# Load the JSON file
with open(file_path, 'r') as file:
vertex_credentials = json.load(file)
# Convert to JSON string
vertex_credentials_json = json.dumps(vertex_credentials)
messages = [
{
"role": "user",
"content": """
List 5 popular cookie recipes.
Using this JSON schema:
Recipe = {"recipe_name": str}
Return a `list[Recipe]`
"""
}
]
completion(model="vertex_ai/gemini-1.5-flash-preview-0514", messages=messages, response_format={ "type": "json_object" })
Grounding
Add Google Search Result grounding to vertex ai calls.
See the grounding metadata with response_obj._hidden_params["vertex_ai_grounding_metadata"]
- SDK
- PROXY
from litellm import completion
## SETUP ENVIRONMENT
# !gcloud auth application-default login - run this to add vertex credentials to your env
tools = [{"googleSearchRetrieval": {}}] # 👈 ADD GOOGLE SEARCH
resp = litellm.completion(
model="vertex_ai/gemini-1.0-pro-001",
messages=[{"role": "user", "content": "Who won the world cup?"}],
tools=tools,
)
print(resp)
curl http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "Hello, Claude!"}
],
"tools": [
{
"googleSearchRetrieval": {}
}
]
}'
Moving from Vertex AI SDK to LiteLLM (GROUNDING)
If this was your initial VertexAI Grounding code,
import vertexai
vertexai.init(project=project_id, location="us-central1")
model = GenerativeModel("gemini-1.5-flash-001")
# Use Google Search for grounding
tool = Tool.from_google_search_retrieval(grounding.GoogleSearchRetrieval(disable_attributon=False))
prompt = "When is the next total solar eclipse in US?"
response = model.generate_content(
prompt,
tools=[tool],
generation_config=GenerationConfig(
temperature=0.0,
),
)
print(response)
then, this is what it looks like now
from litellm import completion
# !gcloud auth application-default login - run this to add vertex credentials to your env
tools = [{"googleSearchRetrieval": {"disable_attributon": False}}] # 👈 ADD GOOGLE SEARCH
resp = litellm.completion(
model="vertex_ai/gemini-1.0-pro-001",
messages=[{"role": "user", "content": "Who won the world cup?"}],
tools=tools,
vertex_project="project-id"
)
print(resp)
Context Caching
Use Vertex AI context caching is supported by calling provider api directly. (Unified Endpoint support comin soon.).
Pre-requisites
pip install google-cloud-aiplatform(pre-installed on proxy docker image)Authentication:
run
gcloud auth application-default loginSee Google Cloud DocsAlternatively you can set
GOOGLE_APPLICATION_CREDENTIALSHere's how: Jump to Code
- Create a service account on GCP
- Export the credentials as a json
- load the json and json.dump the json as a string
- store the json string in your environment as
GOOGLE_APPLICATION_CREDENTIALS
Sample Usage
import litellm
litellm.vertex_project = "hardy-device-38811" # Your Project ID
litellm.vertex_location = "us-central1" # proj location
response = litellm.completion(model="gemini-pro", messages=[{"role": "user", "content": "write code for saying hi from LiteLLM"}])
Usage with LiteLLM Proxy Server
Here's how to use Vertex AI with the LiteLLM Proxy Server
Modify the config.yaml
- Different location per model
- One location all vertex models
Use this when you need to set a different location for each vertex model
model_list:
- model_name: gemini-vision
litellm_params:
model: vertex_ai/gemini-1.0-pro-vision-001
vertex_project: "project-id"
vertex_location: "us-central1"
- model_name: gemini-vision
litellm_params:
model: vertex_ai/gemini-1.0-pro-vision-001
vertex_project: "project-id2"
vertex_location: "us-east"Use this when you have one vertex location for all models
litellm_settings:
vertex_project: "hardy-device-38811" # Your Project ID
vertex_location: "us-central1" # proj location
model_list:
-model_name: team1-gemini-pro
litellm_params:
model: gemini-proStart the proxy
$ litellm --config /path/to/config.yamlSend Request to LiteLLM Proxy Server
- OpenAI Python v1.0.0+
- curl
import openai
client = openai.OpenAI(
api_key="sk-1234", # pass litellm proxy key, if you're using virtual keys
base_url="http://0.0.0.0:4000" # litellm-proxy-base url
)
response = client.chat.completions.create(
model="team1-gemini-pro",
messages = [
{
"role": "user",
"content": "what llm are you"
}
],
)
print(response)curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "team1-gemini-pro",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
Specifying Safety Settings
In certain use-cases you may need to make calls to the models and pass safety settigns different from the defaults. To do so, simple pass the safety_settings argument to completion or acompletion. For example:
Set per model/request
- SDK
- Proxy
response = completion(
model="vertex_ai/gemini-pro",
messages=[{"role": "user", "content": "write code for saying hi from LiteLLM"}]
safety_settings=[
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE",
},
]
)
Option 1: Set in config
model_list:
- model_name: gemini-experimental
litellm_params:
model: vertex_ai/gemini-experimental
vertex_project: litellm-epic
vertex_location: us-central1
safety_settings:
- category: HARM_CATEGORY_HARASSMENT
threshold: BLOCK_NONE
- category: HARM_CATEGORY_HATE_SPEECH
threshold: BLOCK_NONE
- category: HARM_CATEGORY_SEXUALLY_EXPLICIT
threshold: BLOCK_NONE
- category: HARM_CATEGORY_DANGEROUS_CONTENT
threshold: BLOCK_NONE
Option 2: Set on call
response = client.chat.completions.create(
model="gemini-experimental",
messages=[
{
"role": "user",
"content": "Can you write exploits?",
}
],
max_tokens=8192,
stream=False,
temperature=0.0,
extra_body={
"safety_settings": [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE",
},
],
}
)
Set Globally
- SDK
- Proxy
import litellm
litellm.set_verbose = True 👈 See RAW REQUEST/RESPONSE
litellm.vertex_ai_safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE",
},
]
response = completion(
model="vertex_ai/gemini-pro",
messages=[{"role": "user", "content": "write code for saying hi from LiteLLM"}]
)
model_list:
- model_name: gemini-experimental
litellm_params:
model: vertex_ai/gemini-experimental
vertex_project: litellm-epic
vertex_location: us-central1
litellm_settings:
vertex_ai_safety_settings:
- category: HARM_CATEGORY_HARASSMENT
threshold: BLOCK_NONE
- category: HARM_CATEGORY_HATE_SPEECH
threshold: BLOCK_NONE
- category: HARM_CATEGORY_SEXUALLY_EXPLICIT
threshold: BLOCK_NONE
- category: HARM_CATEGORY_DANGEROUS_CONTENT
threshold: BLOCK_NONE
Set Vertex Project & Vertex Location
All calls using Vertex AI require the following parameters:
- Your Project ID
import os, litellm
# set via env var
os.environ["VERTEXAI_PROJECT"] = "hardy-device-38811" # Your Project ID`
### OR ###
# set directly on module
litellm.vertex_project = "hardy-device-38811" # Your Project ID`
- Your Project Location
import os, litellm
# set via env var
os.environ["VERTEXAI_LOCATION"] = "us-central1 # Your Location
### OR ###
# set directly on module
litellm.vertex_location = "us-central1 # Your Location
Anthropic
| Model Name | Function Call |
|---|---|
| claude-3-opus@20240229 | completion('vertex_ai/claude-3-opus@20240229', messages) |
| claude-3-5-sonnet@20240620 | completion('vertex_ai/claude-3-5-sonnet@20240620', messages) |
| claude-3-sonnet@20240229 | completion('vertex_ai/claude-3-sonnet@20240229', messages) |
| claude-3-haiku@20240307 | completion('vertex_ai/claude-3-haiku@20240307', messages) |
Usage
- SDK
- Proxy
from litellm import completion
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = ""
model = "claude-3-sonnet@20240229"
vertex_ai_project = "your-vertex-project" # can also set this as os.environ["VERTEXAI_PROJECT"]
vertex_ai_location = "your-vertex-location" # can also set this as os.environ["VERTEXAI_LOCATION"]
response = completion(
model="vertex_ai/" + model,
messages=[{"role": "user", "content": "hi"}],
temperature=0.7,
vertex_ai_project=vertex_ai_project,
vertex_ai_location=vertex_ai_location,
)
print("\nModel Response", response)
1. Add to config
model_list:
- model_name: anthropic-vertex
litellm_params:
model: vertex_ai/claude-3-sonnet@20240229
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-east-1"
- model_name: anthropic-vertex
litellm_params:
model: vertex_ai/claude-3-sonnet@20240229
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-west-1"
2. Start proxy
litellm --config /path/to/config.yaml
# RUNNING at http://0.0.0.0:4000
3. Test it!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "anthropic-vertex", # 👈 the 'model_name' in config
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
Llama 3 API
| Model Name | Function Call |
|---|---|
| meta/llama3-405b-instruct-maas | completion('vertex_ai/meta/llama3-405b-instruct-maas', messages) |
Usage
- SDK
- Proxy
from litellm import completion
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = ""
model = "meta/llama3-405b-instruct-maas"
vertex_ai_project = "your-vertex-project" # can also set this as os.environ["VERTEXAI_PROJECT"]
vertex_ai_location = "your-vertex-location" # can also set this as os.environ["VERTEXAI_LOCATION"]
response = completion(
model="vertex_ai/" + model,
messages=[{"role": "user", "content": "hi"}],
vertex_ai_project=vertex_ai_project,
vertex_ai_location=vertex_ai_location,
)
print("\nModel Response", response)
1. Add to config
model_list:
- model_name: anthropic-llama
litellm_params:
model: vertex_ai/meta/llama3-405b-instruct-maas
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-east-1"
- model_name: anthropic-llama
litellm_params:
model: vertex_ai/meta/llama3-405b-instruct-maas
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-west-1"
2. Start proxy
litellm --config /path/to/config.yaml
# RUNNING at http://0.0.0.0:4000
3. Test it!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "anthropic-llama", # 👈 the 'model_name' in config
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
Mistral API
| Model Name | Function Call |
|---|---|
| mistral-large@latest | completion('vertex_ai/mistral-large@latest', messages) |
| mistral-large@2407 | completion('vertex_ai/mistral-large@2407', messages) |
| mistral-nemo@latest | completion('vertex_ai/mistral-nemo@latest', messages) |
| codestral@latest | completion('vertex_ai/codestral@latest', messages) |
| codestral@@2405 | completion('vertex_ai/codestral@2405', messages) |
Usage
- SDK
- Proxy
from litellm import completion
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = ""
model = "mistral-large@2407"
vertex_ai_project = "your-vertex-project" # can also set this as os.environ["VERTEXAI_PROJECT"]
vertex_ai_location = "your-vertex-location" # can also set this as os.environ["VERTEXAI_LOCATION"]
response = completion(
model="vertex_ai/" + model,
messages=[{"role": "user", "content": "hi"}],
vertex_ai_project=vertex_ai_project,
vertex_ai_location=vertex_ai_location,
)
print("\nModel Response", response)
1. Add to config
model_list:
- model_name: vertex-mistral
litellm_params:
model: vertex_ai/mistral-large@2407
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-east-1"
- model_name: vertex-mistral
litellm_params:
model: vertex_ai/mistral-large@2407
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-west-1"
2. Start proxy
litellm --config /path/to/config.yaml
# RUNNING at http://0.0.0.0:4000
3. Test it!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "vertex-mistral", # 👈 the 'model_name' in config
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
AI21 Models
| Model Name | Function Call |
|---|---|
| jamba-1.5-mini@001 | completion(model='vertex_ai/jamba-1.5-mini@001', messages) |
| jamba-1.5-large@001 | completion(model='vertex_ai/jamba-1.5-large@001', messages) |
Usage
- SDK
- Proxy
from litellm import completion
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = ""
model = "meta/jamba-1.5-mini@001"
vertex_ai_project = "your-vertex-project" # can also set this as os.environ["VERTEXAI_PROJECT"]
vertex_ai_location = "your-vertex-location" # can also set this as os.environ["VERTEXAI_LOCATION"]
response = completion(
model="vertex_ai/" + model,
messages=[{"role": "user", "content": "hi"}],
vertex_ai_project=vertex_ai_project,
vertex_ai_location=vertex_ai_location,
)
print("\nModel Response", response)
1. Add to config
model_list:
- model_name: jamba-1.5-mini
litellm_params:
model: vertex_ai/jamba-1.5-mini@001
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-east-1"
- model_name: jamba-1.5-large
litellm_params:
model: vertex_ai/jamba-1.5-large@001
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-west-1"
2. Start proxy
litellm --config /path/to/config.yaml
# RUNNING at http://0.0.0.0:4000
3. Test it!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "jamba-1.5-large",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
Usage - Codestral FIM
Call Codestral on VertexAI via the OpenAI /v1/completion endpoint for FIM tasks.
Note: You can also call Codestral via /chat/completion.
- SDK
- Proxy
from litellm import completion
import os
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = ""
# OR run `!gcloud auth print-access-token` in your terminal
model = "codestral@2405"
vertex_ai_project = "your-vertex-project" # can also set this as os.environ["VERTEXAI_PROJECT"]
vertex_ai_location = "your-vertex-location" # can also set this as os.environ["VERTEXAI_LOCATION"]
response = text_completion(
model="vertex_ai/" + model,
vertex_ai_project=vertex_ai_project,
vertex_ai_location=vertex_ai_location,
prompt="def is_odd(n): \n return n % 2 == 1 \ndef test_is_odd():",
suffix="return True", # optional
temperature=0, # optional
top_p=1, # optional
max_tokens=10, # optional
min_tokens=10, # optional
seed=10, # optional
stop=["return"], # optional
)
print("\nModel Response", response)
1. Add to config
model_list:
- model_name: vertex-codestral
litellm_params:
model: vertex_ai/codestral@2405
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-east-1"
- model_name: vertex-codestral
litellm_params:
model: vertex_ai/codestral@2405
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-west-1"
2. Start proxy
litellm --config /path/to/config.yaml
# RUNNING at http://0.0.0.0:4000
3. Test it!
curl -X POST 'http://0.0.0.0:4000/completions' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{
"model": "vertex-codestral", # 👈 the 'model_name' in config
"prompt": "def is_odd(n): \n return n % 2 == 1 \ndef test_is_odd():",
"suffix":"return True", # optional
"temperature":0, # optional
"top_p":1, # optional
"max_tokens":10, # optional
"min_tokens":10, # optional
"seed":10, # optional
"stop":["return"], # optional
}'
Model Garden
| Model Name | Function Call |
|---|---|
| llama2 | completion('vertex_ai/<endpoint_id>', messages) |
Using Model Garden
from litellm import completion
import os
## set ENV variables
os.environ["VERTEXAI_PROJECT"] = "hardy-device-38811"
os.environ["VERTEXAI_LOCATION"] = "us-central1"
response = completion(
model="vertex_ai/<your-endpoint-id>",
messages=[{ "content": "Hello, how are you?","role": "user"}]
)
Gemini Pro
| Model Name | Function Call |
|---|---|
| gemini-pro | completion('gemini-pro', messages), completion('vertex_ai/gemini-pro', messages) |
Fine-tuned Models
Fine tuned models on vertex have a numerical model/endpoint id.
- SDK
- PROXY
from litellm import completion
import os
## set ENV variables
os.environ["VERTEXAI_PROJECT"] = "hardy-device-38811"
os.environ["VERTEXAI_LOCATION"] = "us-central1"
response = completion(
model="vertex_ai/<your-finetuned-model>", # e.g. vertex_ai/4965075652664360960
messages=[{ "content": "Hello, how are you?","role": "user"}],
base_model="vertex_ai/gemini-1.5-pro" # the base model - used for routing
)
- Add Vertex Credentials to your env
!gcloud auth application-default login
- Setup config.yaml
- model_name: finetuned-gemini
litellm_params:
model: vertex_ai/<ENDPOINT_ID>
vertex_project: <PROJECT_ID>
vertex_location: <LOCATION>
model_info:
base_model: vertex_ai/gemini-1.5-pro # IMPORTANT
- Test it!
curl --location 'https://0.0.0.0:4000/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: <LITELLM_KEY>' \
--data '{"model": "finetuned-gemini" ,"messages":[{"role": "user", "content":[{"type": "text", "text": "hi"}]}]}'
Gemini Pro Vision
| Model Name | Function Call |
|---|---|
| gemini-pro-vision | completion('gemini-pro-vision', messages), completion('vertex_ai/gemini-pro-vision', messages) |
Gemini 1.5 Pro (and Vision)
| Model Name | Function Call |
|---|---|
| gemini-1.5-pro | completion('gemini-1.5-pro', messages), completion('vertex_ai/gemini-1.5-pro', messages) |
| gemini-1.5-flash-preview-0514 | completion('gemini-1.5-flash-preview-0514', messages), completion('vertex_ai/gemini-1.5-flash-preview-0514', messages) |
| gemini-1.5-pro-preview-0514 | completion('gemini-1.5-pro-preview-0514', messages), completion('vertex_ai/gemini-1.5-pro-preview-0514', messages) |
Using Gemini Pro Vision
Call gemini-pro-vision in the same input/output format as OpenAI gpt-4-vision
LiteLLM Supports the following image types passed in url
- Images with Cloud Storage URIs - gs://cloud-samples-data/generative-ai/image/boats.jpeg
- Images with direct links - https://storage.googleapis.com/github-repo/img/gemini/intro/landmark3.jpg
- Videos with Cloud Storage URIs - https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/pixel8.mp4
- Base64 Encoded Local Images
Example Request - image url
- Images with direct links
- Local Base64 Images
import litellm
response = litellm.completion(
model = "vertex_ai/gemini-pro-vision",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Whats in this image?"
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
}
}
]
}
],
)
print(response)
import litellm
def encode_image(image_path):
import base64
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
image_path = "cached_logo.jpg"
# Getting the base64 string
base64_image = encode_image(image_path)
response = litellm.completion(
model="vertex_ai/gemini-pro-vision",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Whats in this image?"},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64," + base64_image
},
},
],
}
],
)
print(response)
Usage - Function Calling
LiteLLM supports Function Calling for Vertex AI gemini models.
from litellm import completion
import os
# set env
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = ".."
os.environ["VERTEX_AI_PROJECT"] = ".."
os.environ["VERTEX_AI_LOCATION"] = ".."
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}
]
messages = [{"role": "user", "content": "What's the weather like in Boston today?"}]
response = completion(
model="vertex_ai/gemini-pro-vision",
messages=messages,
tools=tools,
)
# Add any assertions, here to check response args
print(response)
assert isinstance(response.choices[0].message.tool_calls[0].function.name, str)
assert isinstance(
response.choices[0].message.tool_calls[0].function.arguments, str
)
Usage - PDF / Videos / etc. Files
Pass any file supported by Vertex AI, through LiteLLM.
- SDK
- proxy
Using gs://
from litellm import completion
response = completion(
model="vertex_ai/gemini-1.5-flash",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "You are a very professional document summarization specialist. Please summarize the given document."},
{
"type": "image_url",
"image_url": "gs://cloud-samples-data/generative-ai/pdf/2403.05530.pdf", # 👈 PDF
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
using base64
from litellm import completion
import base64
import requests
# URL of the file
url = "https://storage.googleapis.com/cloud-samples-data/generative-ai/pdf/2403.05530.pdf"
# Download the file
response = requests.get(url)
file_data = response.content
encoded_file = base64.b64encode(file_data).decode("utf-8")
response = completion(
model="vertex_ai/gemini-1.5-flash",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "You are a very professional document summarization specialist. Please summarize the given document."},
{
"type": "image_url",
"image_url": f"data:application/pdf;base64,{encoded_file}", # 👈 PDF
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
- Add model to config
- model_name: gemini-1.5-flash
litellm_params:
model: vertex_ai/gemini-1.5-flash
vertex_credentials: "/path/to/service_account.json"
- Start Proxy
litellm --config /path/to/config.yaml
- Test it!
Using gs://
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-LITELLM-KEY>" \
-d '{
"model": "gemini-1.5-flash",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "You are a very professional document summarization specialist. Please summarize the given document"
},
{
"type": "image_url",
"image_url": "gs://cloud-samples-data/generative-ai/pdf/2403.05530.pdf" # 👈 PDF
}
}
]
}
],
"max_tokens": 300
}'
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-LITELLM-KEY>" \
-d '{
"model": "gemini-1.5-flash",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "You are a very professional document summarization specialist. Please summarize the given document"
},
{
"type": "image_url",
"image_url": "data:application/pdf;base64,{encoded_file}" # 👈 PDF
}
}
]
}
],
"max_tokens": 300
}'
Chat Models
| Model Name | Function Call |
|---|---|
| chat-bison-32k | completion('chat-bison-32k', messages) |
| chat-bison | completion('chat-bison', messages) |
| chat-bison@001 | completion('chat-bison@001', messages) |
Code Chat Models
| Model Name | Function Call |
|---|---|
| codechat-bison | completion('codechat-bison', messages) |
| codechat-bison-32k | completion('codechat-bison-32k', messages) |
| codechat-bison@001 | completion('codechat-bison@001', messages) |
Text Models
| Model Name | Function Call |
|---|---|
| text-bison | completion('text-bison', messages) |
| text-bison@001 | completion('text-bison@001', messages) |
Code Text Models
| Model Name | Function Call |
|---|---|
| code-bison | completion('code-bison', messages) |
| code-bison@001 | completion('code-bison@001', messages) |
| code-gecko@001 | completion('code-gecko@001', messages) |
| code-gecko@latest | completion('code-gecko@latest', messages) |
Embedding Models
Usage - Embedding
import litellm
from litellm import embedding
litellm.vertex_project = "hardy-device-38811" # Your Project ID
litellm.vertex_location = "us-central1" # proj location
response = embedding(
model="vertex_ai/textembedding-gecko",
input=["good morning from litellm"],
)
print(response)
Supported Embedding Models
All models listed here are supported
| Model Name | Function Call |
|---|---|
| text-embedding-004 | embedding(model="vertex_ai/text-embedding-004", input) |
| text-multilingual-embedding-002 | embedding(model="vertex_ai/text-multilingual-embedding-002", input) |
| textembedding-gecko | embedding(model="vertex_ai/textembedding-gecko", input) |
| textembedding-gecko-multilingual | embedding(model="vertex_ai/textembedding-gecko-multilingual", input) |
| textembedding-gecko-multilingual@001 | embedding(model="vertex_ai/textembedding-gecko-multilingual@001", input) |
| textembedding-gecko@001 | embedding(model="vertex_ai/textembedding-gecko@001", input) |
| textembedding-gecko@003 | embedding(model="vertex_ai/textembedding-gecko@003", input) |
| text-embedding-preview-0409 | embedding(model="vertex_ai/text-embedding-preview-0409", input) |
| text-multilingual-embedding-preview-0409 | embedding(model="vertex_ai/text-multilingual-embedding-preview-0409", input) |
Supported OpenAI (Unified) Params
| param | type | vertex equivalent |
|---|---|---|
input | string or List[string] | instances |
dimensions | int | output_dimensionality |
input_type | Literal["RETRIEVAL_QUERY","RETRIEVAL_DOCUMENT", "SEMANTIC_SIMILARITY", "CLASSIFICATION", "CLUSTERING", "QUESTION_ANSWERING", "FACT_VERIFICATION"] | task_type |
Usage with OpenAI (Unified) Params
- SDK
- LiteLLM PROXY
response = litellm.embedding(
model="vertex_ai/text-embedding-004",
input=["good morning from litellm", "gm"]
input_type = "RETRIEVAL_DOCUMENT",
dimensions=1,
)
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
response = client.embeddings.create(
model="text-embedding-004",
input = ["good morning from litellm", "gm"],
dimensions=1,
extra_body = {
"input_type": "RETRIEVAL_QUERY",
}
)
print(response)
Supported Vertex Specific Params
| param | type |
|---|---|
auto_truncate | bool |
task_type | Literal["RETRIEVAL_QUERY","RETRIEVAL_DOCUMENT", "SEMANTIC_SIMILARITY", "CLASSIFICATION", "CLUSTERING", "QUESTION_ANSWERING", "FACT_VERIFICATION"] |
title | str |
Usage with Vertex Specific Params (Use task_type and title)
You can pass any vertex specific params to the embedding model. Just pass them to the embedding function like this:
Relevant Vertex AI doc with all embedding params
- SDK
- LiteLLM PROXY
response = litellm.embedding(
model="vertex_ai/text-embedding-004",
input=["good morning from litellm", "gm"]
task_type = "RETRIEVAL_DOCUMENT",
title = "test",
dimensions=1,
auto_truncate=True,
)
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
response = client.embeddings.create(
model="text-embedding-004",
input = ["good morning from litellm", "gm"],
dimensions=1,
extra_body = {
"task_type": "RETRIEVAL_QUERY",
"auto_truncate": True,
"title": "test",
}
)
print(response)
Multi-Modal Embeddings
Usage
- SDK
- LiteLLM PROXY (Unified Endpoint)
- LiteLLM PROXY (Vertex SDK)
response = await litellm.aembedding(
model="vertex_ai/multimodalembedding@001",
input=[
{
"image": {
"gcsUri": "gs://cloud-samples-data/vertex-ai/llm/prompts/landmark1.png"
},
"text": "this is a unicorn",
},
],
)
- Add model to config.yaml
model_list:
- model_name: multimodalembedding@001
litellm_params:
model: vertex_ai/multimodalembedding@001
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: adroit-crow-413218-a956eef1a2a8.json
litellm_settings:
drop_params: True
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request use OpenAI Python SDK
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
# # request sent to model set on litellm proxy, `litellm --model`
response = client.embeddings.create(
model="multimodalembedding@001",
input = None,
extra_body = {
"instances": [
{
"image": {
"bytesBase64Encoded": "base64"
},
"text": "this is a unicorn",
},
],
}
)
print(response)
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
# # request sent to model set on litellm proxy, `litellm --model`
response = client.embeddings.create(
model="multimodalembedding@001",
input = None,
extra_body = {
"instances": [
{
"image": {
"gcsUri": "gs://cloud-samples-data/vertex-ai/llm/prompts/landmark1.png"
},
"text": "this is a unicorn",
},
],
}
)
print(response)
- Add model to config.yaml
default_vertex_config:
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: adroit-crow-413218-a956eef1a2a8.json
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request use OpenAI Python SDK
import vertexai
from vertexai.vision_models import Image, MultiModalEmbeddingModel, Video
from vertexai.vision_models import VideoSegmentConfig
from google.auth.credentials import Credentials
LITELLM_PROXY_API_KEY = "sk-1234"
LITELLM_PROXY_BASE = "http://0.0.0.0:4000/vertex-ai"
import datetime
class CredentialsWrapper(Credentials):
def __init__(self, token=None):
super().__init__()
self.token = token
self.expiry = None # or set to a future date if needed
def refresh(self, request):
pass
def apply(self, headers, token=None):
headers['Authorization'] = f'Bearer {self.token}'
@property
def expired(self):
return False # Always consider the token as non-expired
@property
def valid(self):
return True # Always consider the credentials as valid
credentials = CredentialsWrapper(token=LITELLM_PROXY_API_KEY)
vertexai.init(
project="adroit-crow-413218",
location="us-central1",
api_endpoint=LITELLM_PROXY_BASE,
credentials = credentials,
api_transport="rest",
)
model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
image = Image.load_from_file(
"gs://cloud-samples-data/vertex-ai/llm/prompts/landmark1.png"
)
embeddings = model.get_embeddings(
image=image,
contextual_text="Colosseum",
dimension=1408,
)
print(f"Image Embedding: {embeddings.image_embedding}")
print(f"Text Embedding: {embeddings.text_embedding}")
Image Generation Models
Usage
response = await litellm.aimage_generation(
prompt="An olympic size swimming pool",
model="vertex_ai/imagegeneration@006",
vertex_ai_project="adroit-crow-413218",
vertex_ai_location="us-central1",
)
Generating multiple images
Use the n parameter to pass how many images you want generated
response = await litellm.aimage_generation(
prompt="An olympic size swimming pool",
model="vertex_ai/imagegeneration@006",
vertex_ai_project="adroit-crow-413218",
vertex_ai_location="us-central1",
n=1,
)
Supported Image Generation Models
| Model Name | FUsage |
|---|---|
imagen-3.0-generate-001 | litellm.image_generation('vertex_ai/imagen-3.0-generate-001', prompt) |
imagen-3.0-fast-generate-001 | litellm.image_generation('vertex_ai/imagen-3.0-fast-generate-001', prompt) |
imagegeneration@006 | litellm.image_generation('vertex_ai/imagegeneration@006', prompt) |
imagegeneration@005 | litellm.image_generation('vertex_ai/imagegeneration@005', prompt) |
imagegeneration@002 | litellm.image_generation('vertex_ai/imagegeneration@002', prompt) |
Text to Speech APIs
LiteLLM supports calling Vertex AI Text to Speech API in the OpenAI text to speech API format
Usage - Basic
- SDK
- LiteLLM PROXY (Unified Endpoint)
Vertex AI does not support passing a model param - so passing model=vertex_ai/ is the only required param
Sync Usage
speech_file_path = Path(__file__).parent / "speech_vertex.mp3"
response = litellm.speech(
model="vertex_ai/",
input="hello what llm guardrail do you have",
)
response.stream_to_file(speech_file_path)
Async Usage
speech_file_path = Path(__file__).parent / "speech_vertex.mp3"
response = litellm.aspeech(
model="vertex_ai/",
input="hello what llm guardrail do you have",
)
response.stream_to_file(speech_file_path)
- Add model to config.yaml
model_list:
- model_name: vertex-tts
litellm_params:
model: vertex_ai/ # Vertex AI does not support passing a `model` param - so passing `model=vertex_ai/` is the only required param
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: adroit-crow-413218-a956eef1a2a8.json
litellm_settings:
drop_params: True
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request use OpenAI Python SDK
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
# see supported values for "voice" on vertex here:
# https://console.cloud.google.com/vertex-ai/generative/speech/text-to-speech
response = client.audio.speech.create(
model = "vertex-tts",
input="the quick brown fox jumped over the lazy dogs",
voice={'languageCode': 'en-US', 'name': 'en-US-Studio-O'}
)
print("response from proxy", response)
Usage - ssml as input
Pass your ssml as input to the input param, if it contains <speak>, it will be automatically detected and passed as ssml to the Vertex AI API
If you need to force your input to be passed as ssml, set use_ssml=True
- SDK
- LiteLLM PROXY (Unified Endpoint)
Vertex AI does not support passing a model param - so passing model=vertex_ai/ is the only required param
speech_file_path = Path(__file__).parent / "speech_vertex.mp3"
ssml = """
<speak>
<p>Hello, world!</p>
<p>This is a test of the <break strength="medium" /> text-to-speech API.</p>
</speak>
"""
response = litellm.speech(
input=ssml,
model="vertex_ai/test",
voice={
"languageCode": "en-UK",
"name": "en-UK-Studio-O",
},
audioConfig={
"audioEncoding": "LINEAR22",
"speakingRate": "10",
},
)
response.stream_to_file(speech_file_path)
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
ssml = """
<speak>
<p>Hello, world!</p>
<p>This is a test of the <break strength="medium" /> text-to-speech API.</p>
</speak>
"""
# see supported values for "voice" on vertex here:
# https://console.cloud.google.com/vertex-ai/generative/speech/text-to-speech
response = client.audio.speech.create(
model = "vertex-tts",
input=ssml,
voice={'languageCode': 'en-US', 'name': 'en-US-Studio-O'},
)
print("response from proxy", response)
Forcing SSML Usage
You can force the use of SSML by setting the use_ssml parameter to True. This is useful when you want to ensure that your input is treated as SSML, even if it doesn't contain the <speak> tags.
Here are examples of how to force SSML usage:
- SDK
- LiteLLM PROXY (Unified Endpoint)
Vertex AI does not support passing a model param - so passing model=vertex_ai/ is the only required param
speech_file_path = Path(__file__).parent / "speech_vertex.mp3"
ssml = """
<speak>
<p>Hello, world!</p>
<p>This is a test of the <break strength="medium" /> text-to-speech API.</p>
</speak>
"""
response = litellm.speech(
input=ssml,
use_ssml=True,
model="vertex_ai/test",
voice={
"languageCode": "en-UK",
"name": "en-UK-Studio-O",
},
audioConfig={
"audioEncoding": "LINEAR22",
"speakingRate": "10",
},
)
response.stream_to_file(speech_file_path)
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
ssml = """
<speak>
<p>Hello, world!</p>
<p>This is a test of the <break strength="medium" /> text-to-speech API.</p>
</speak>
"""
# see supported values for "voice" on vertex here:
# https://console.cloud.google.com/vertex-ai/generative/speech/text-to-speech
response = client.audio.speech.create(
model = "vertex-tts",
input=ssml, # pass as None since OpenAI SDK requires this param
voice={'languageCode': 'en-US', 'name': 'en-US-Studio-O'},
extra_body={"use_ssml": True},
)
print("response from proxy", response)
Extra
Using GOOGLE_APPLICATION_CREDENTIALS
Here's the code for storing your service account credentials as GOOGLE_APPLICATION_CREDENTIALS environment variable:
def load_vertex_ai_credentials():
# Define the path to the vertex_key.json file
print("loading vertex ai credentials")
filepath = os.path.dirname(os.path.abspath(__file__))
vertex_key_path = filepath + "/vertex_key.json"
# Read the existing content of the file or create an empty dictionary
try:
with open(vertex_key_path, "r") as file:
# Read the file content
print("Read vertexai file path")
content = file.read()
# If the file is empty or not valid JSON, create an empty dictionary
if not content or not content.strip():
service_account_key_data = {}
else:
# Attempt to load the existing JSON content
file.seek(0)
service_account_key_data = json.load(file)
except FileNotFoundError:
# If the file doesn't exist, create an empty dictionary
service_account_key_data = {}
# Create a temporary file
with tempfile.NamedTemporaryFile(mode="w+", delete=False) as temp_file:
# Write the updated content to the temporary file
json.dump(service_account_key_data, temp_file, indent=2)
# Export the temporary file as GOOGLE_APPLICATION_CREDENTIALS
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = os.path.abspath(temp_file.name)
Using GCP Service Account
Trying to deploy LiteLLM on Google Cloud Run? Tutorial here
- Figure out the Service Account bound to the Google Cloud Run service
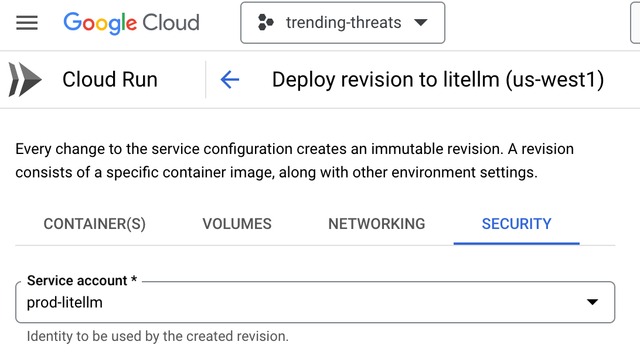
Get the FULL EMAIL address of the corresponding Service Account
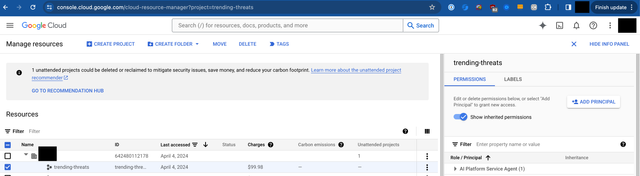
Next, go to IAM & Admin > Manage Resources , select your top-level project that houses your Google Cloud Run Service
Click Add Principal
- Specify the Service Account as the principal and Vertex AI User as the role
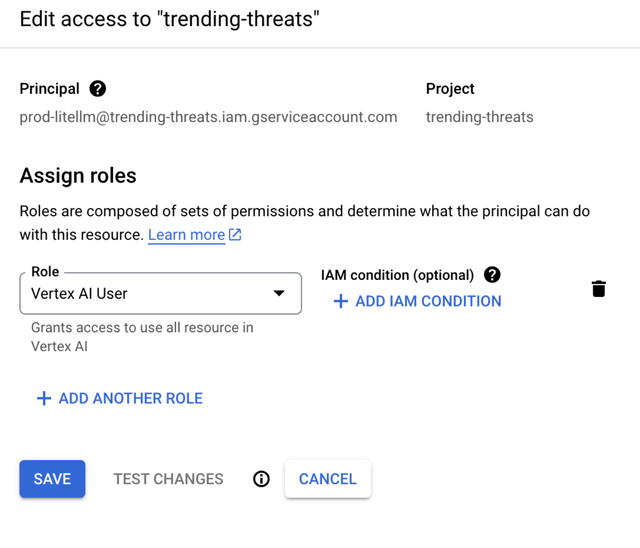
Once that's done, when you deploy the new container in the Google Cloud Run service, LiteLLM will have automatic access to all Vertex AI endpoints.
s/o @Darien Kindlund for this tutorial